How well do multi-modal LLMs hear Mandarin tones? Do they hear tones? Let's find out!
by Yunus Abdülhayoğlu <hi@lingolingo.app>
After reading this article https://simedw.com/2026/01/31/ear-pronunication-via-ctc/ and exploring the failure cases (see above), I was curious to see if multi-modal LLMs could hear Mandarin tones. Especially since the article references the "bitter lesson":
Wouldn't it be funny if an article referencing the bitter lesson could suffer from the same bitter lesson? Okay, that's not really funny. But it's certainly interesting. By the way, I'm not trying to take away from the accomplishments of the original article. Even if SOTA LLMs can achieve similar results, there's still value in a small model that can run locally with low latency and for free.And if there’s one thing we’ve learned over the last decade, it’s the bitter lesson: when you have enough data and compute, learned representations usually beat carefully hand-tuned systems.
Results
The results indicate that there is some emergent ability to hear Mandarin tones in off-the-shelf multi-modal LLMs, most notably Gemini 3.0 Pro.
Documenting My Approach
For this article, I want to try something new. I'm including my full chat transcript from Cursor to show how I'm interacting with the AI agent. I'm doing this for three reasons:
- The initial prompt works well as an intro for this article. The reader and the LLM are actually in the same position of needing context and an overview, and the prompt delivers that in a information-dense way.
- For transparency, so the reader can follow the raw process.
- To contribute to the discussion about documenting the use of AI when coding.
Notes:
- The transcript is missing some information, like the mode the agent was in (plan, ask, debug, agent)
- The text starting with "Implement the plan as specified [...]" is actually injected by Cursor as user input, when you approve a plan that was created in "plan" mode
- Also missing are manual actions, e.g. when I manually stop the agent or reject a command
- Normally I would start a new chat more frequently to keep the context clean, but here I wanted to keep everything in one chat for easier publishing
- I like letting the agent run commands instead of running them myself (I approve each command manually). This does two things: 1. The agent can read the output of the command and plan the next steps or fix errors. 2. It's a canary specifically when using conda. Eventually the agent "forgets" to use the conda env, which tells me that the context window has been exhausted and I should probably start a new chat.
- At the end, I actually had to start a new chat because I was hitting diminishing returns. That chat is not included to keep things simple.
Paper referenced: https://arxiv.org/abs/2104.05657
1. The Four Tones
In Mandarin, each syllable carries one of four tones, with an additional unstressed one, which we ignore here:
- T1 — flat, relatively high
- T2 — rising
- T3 — dip then rise
- T4 — fall from high to low
The figure below shows the idealized pitch contours that we use for the synthetic tones.
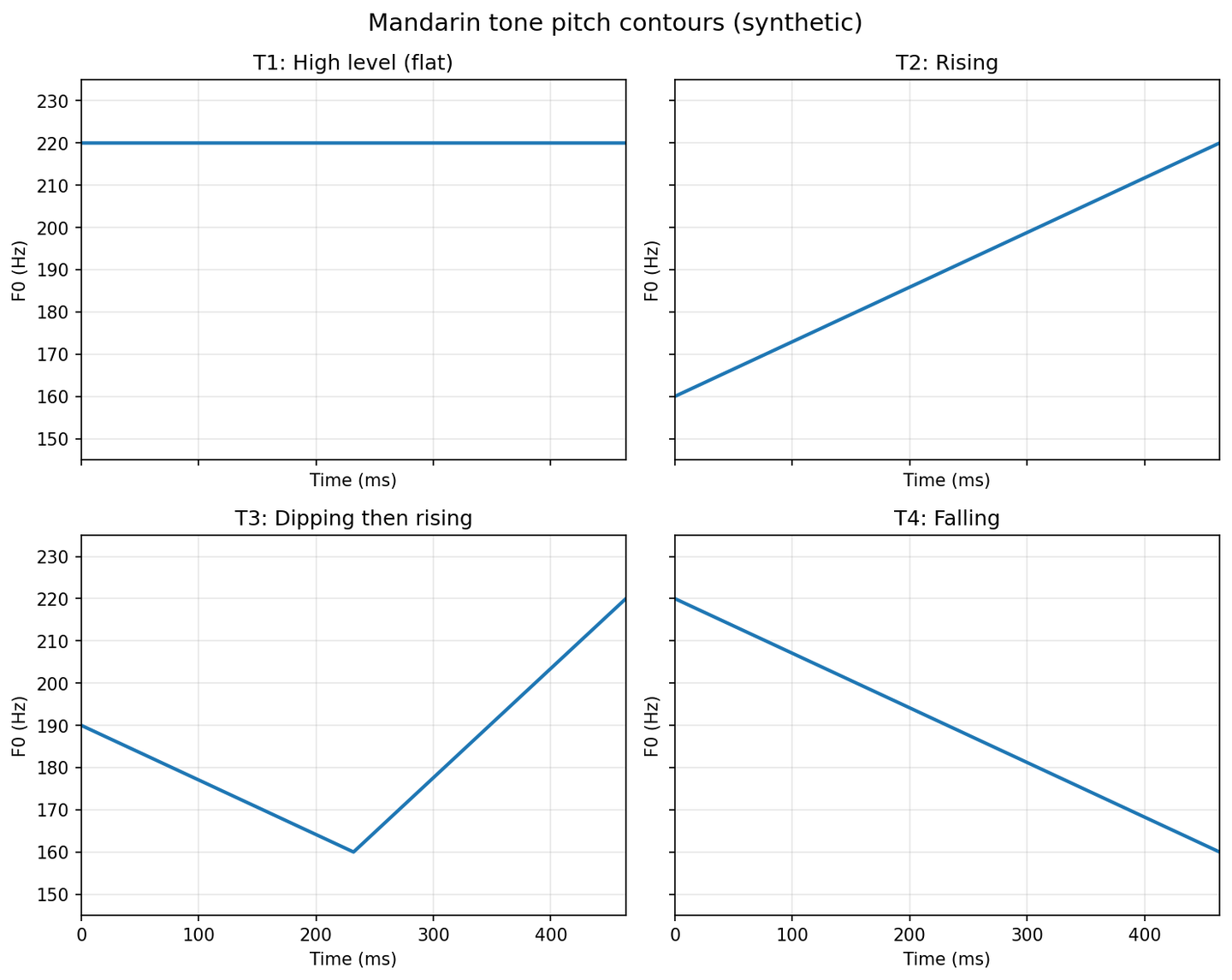
2. Synthetic Tones
The synthetic audio that we created.
Synthetic tones (T1–T4)
3. Native Speaker Pronouncing “bai” (T1–T4)
Four real Mandarin syllables from https://github.com/hugolpz/audio-cmn
bai1, bai2, bai3, bai4
3. Testing Synthetic tones
I tested the endpoints with the raw pitch audio, but the models were not able to distinguish any tones. This indicates that the detection of tones is tightly coupled with the phoetic form of the syllables and can't be referenced in an abstract way.
| Model | Stimulus T1 → pred | T2 → pred | T3 → pred | T4 → pred | Correct |
|---|---|---|---|---|---|
| GPT Audio (2025-08-28) | 3 | 2 | 4 | 2 | 0/4 |
| GPT-4o Audio | 3 | 3 | 4 | 4 | 0/4 |
| Gemini 2.0 Flash | 4 | 4 | 4 | 4 | 0/4 |
| Gemini 2.5 Pro | 3 | 4 | 4 | 1 | 0/4 |
| Gemini 3.0 Pro | 1 | 3 | 4 | 3 | 1/4 |
| Gemini 3.1 Pro | 2 | 2 | — | 3 | 1/4 |
5. Testing with Real Syllables
Macro F1 (average of per-tone F1) on the 60-clip set. Random baseline ≈ 0.25.
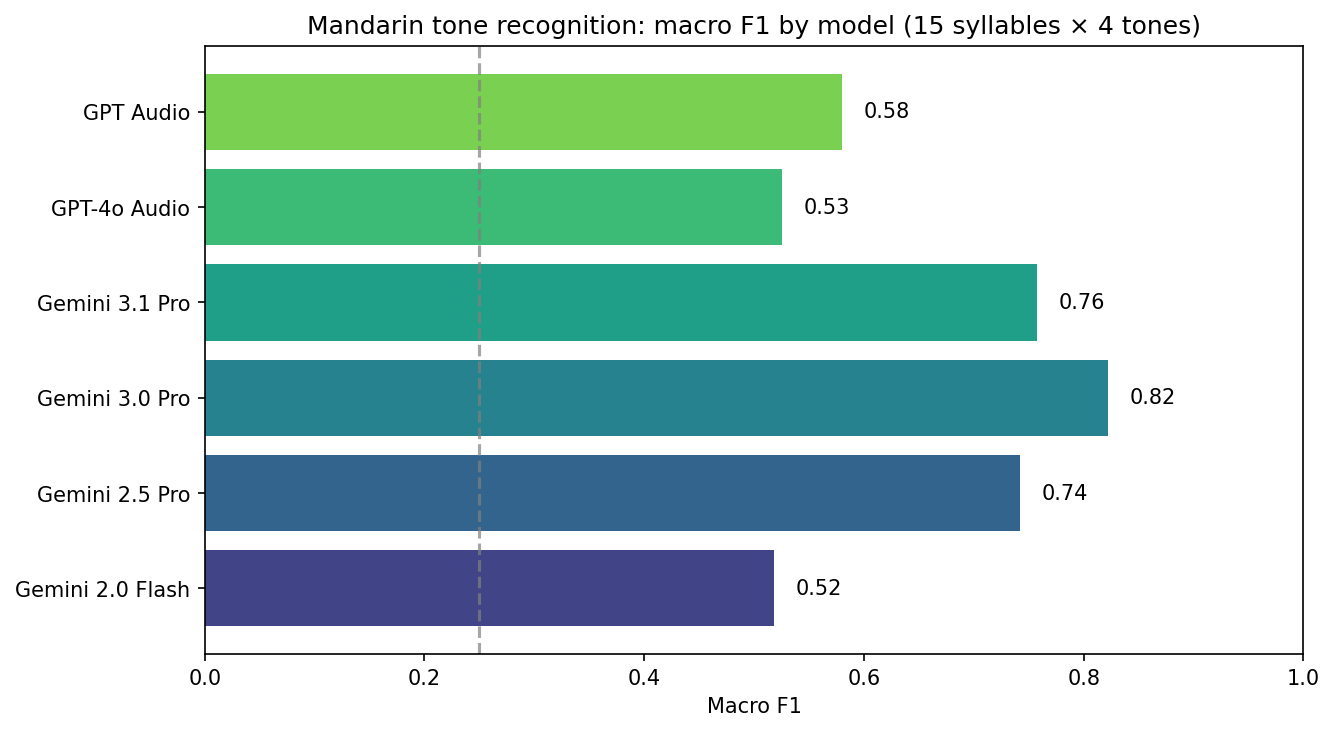
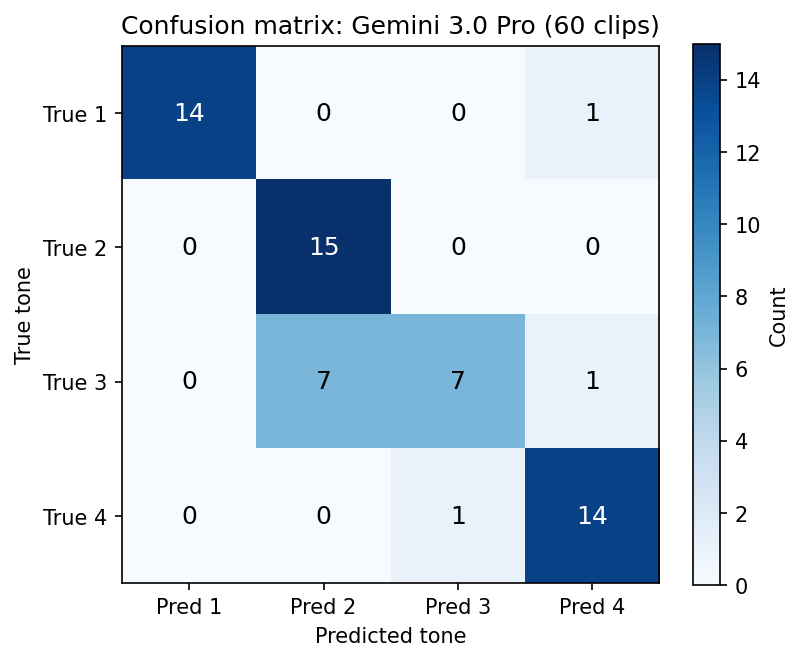
| Model | Macro F1 |
|---|---|
| Gemini 3.0 Pro | 0.82 |
| Gemini 3.1 Pro | 0.76 |
| Gemini 2.5 Pro | 0.74 |
| GPT Audio (2025-08-28) | 0.58 |
| GPT-4o Audio | 0.53 |
| Gemini 2.0 Flash | 0.52 |
When interpreting: high recall on T4 or a tendency to predict “4” can reflect the Mandarin tone prior as well as acoustic discrimination.
5.2 Syllable “hao” (4 clips)
Same models on four clips for the syllable hao (hao1–hao4). Interestingly, the performance is much worse, with the model erring towards the third and fourth tone. A possible explanation here is that there are basically no words in Mandarin that use hao1, and while hao2 is more common, it is still orders of magnitudes less used than hao3 (most commonly 好, "good") and hao4 (號, "number"), which are among the most commonly used words in Mandarin. This of course would have to be taken into account when considering these systems for serious use.
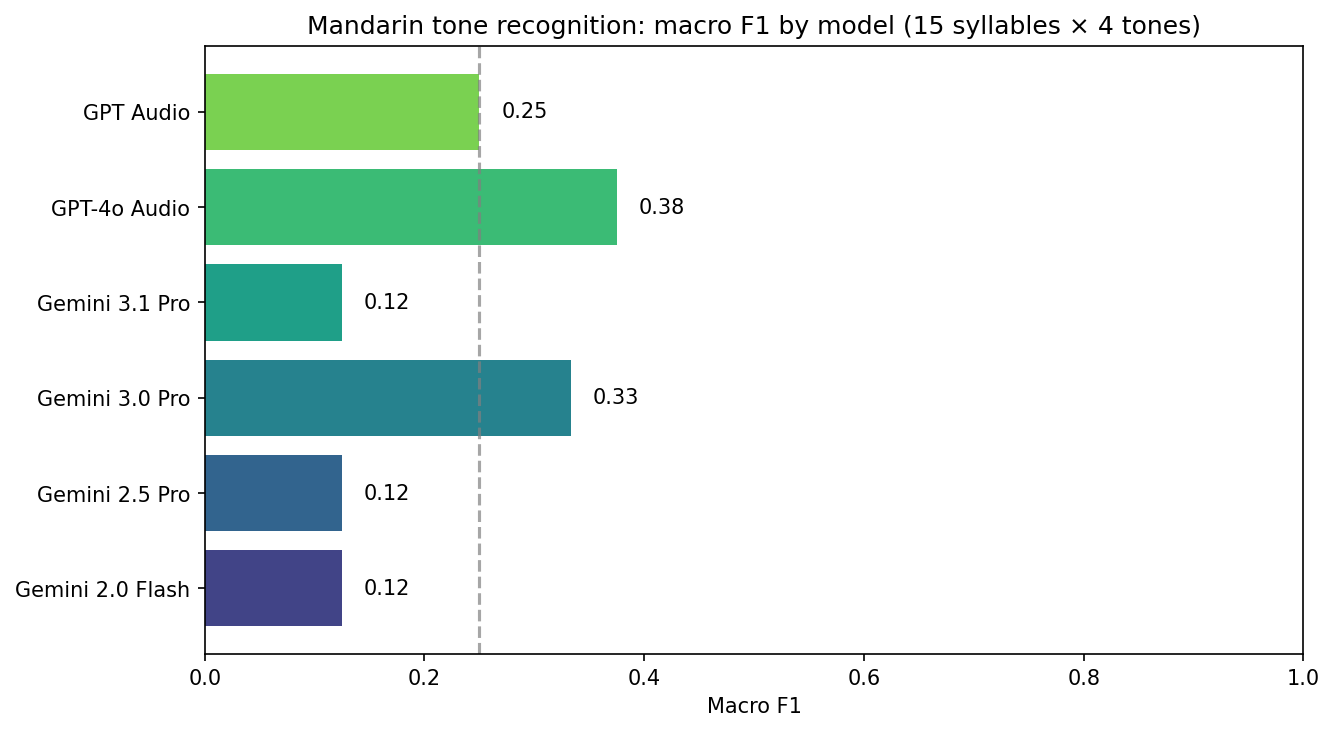
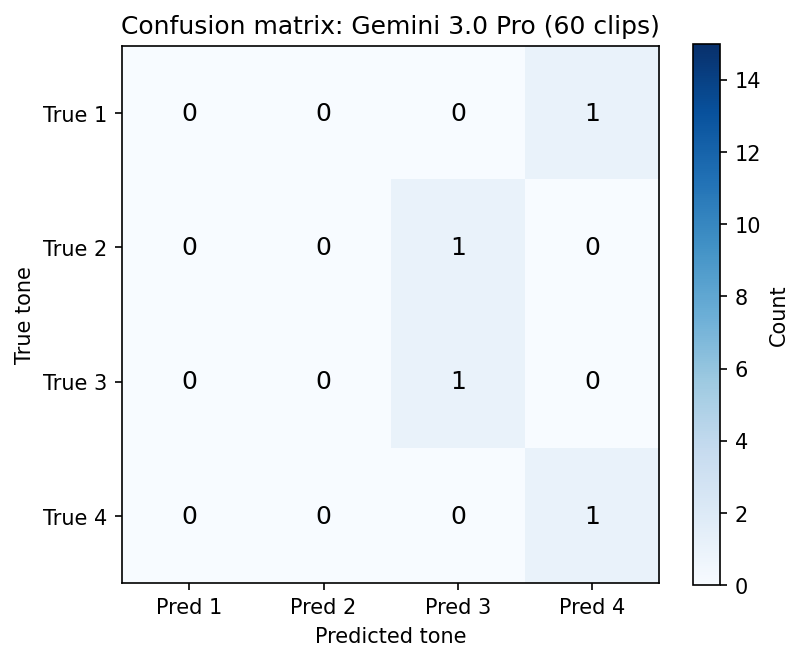
| Model | T1 → pred | T2 → pred | T3 → pred | T4 → pred | Correct |
|---|---|---|---|---|---|
| Gemini 3.0 Pro | 4 | 3 | 3 | 4 | 3/4 |
| GPT-4o Audio | 4 | 4 | 3 | 4 | 2/4 |
| GPT Audio (2025-08-28) | — | — | — | 4 | 1/4 |
| Gemini 2.5 Pro | 4 | 3 | 3 | 3 | 1/4 |
| Gemini 2.0 Flash | 3 | — | 3 | 3 | 1/4 |
| Gemini 3.1 Pro | 3 | 3 | 3 | — | 1/4 |
GPT Audio returned no tone for hao1–hao3; Gemini 2.0 Flash had no response for hao2; Gemini 3.1 Pro timed out on hao4.
6. Trying Something Different
With the results being promising, but still far from perfect, I had another idea: what if we add another modality, namely images, to provide more context to the LLM? The idea is to pass a F0 frequency graph to the model, so it can visually "see" the tone contour. For this, Praat is the gold standard, so I used my existing Praat integration from LingoLingo to generate tone pitch contours and passed them to Gemini 3.0 Pro. This method proved to be very effective and lead to a macro F1 of 92%. Unfortunately, due to the added latency of Praat and the added modality, requests took up to 20 seconds to complete, which would be too much for a real world application.
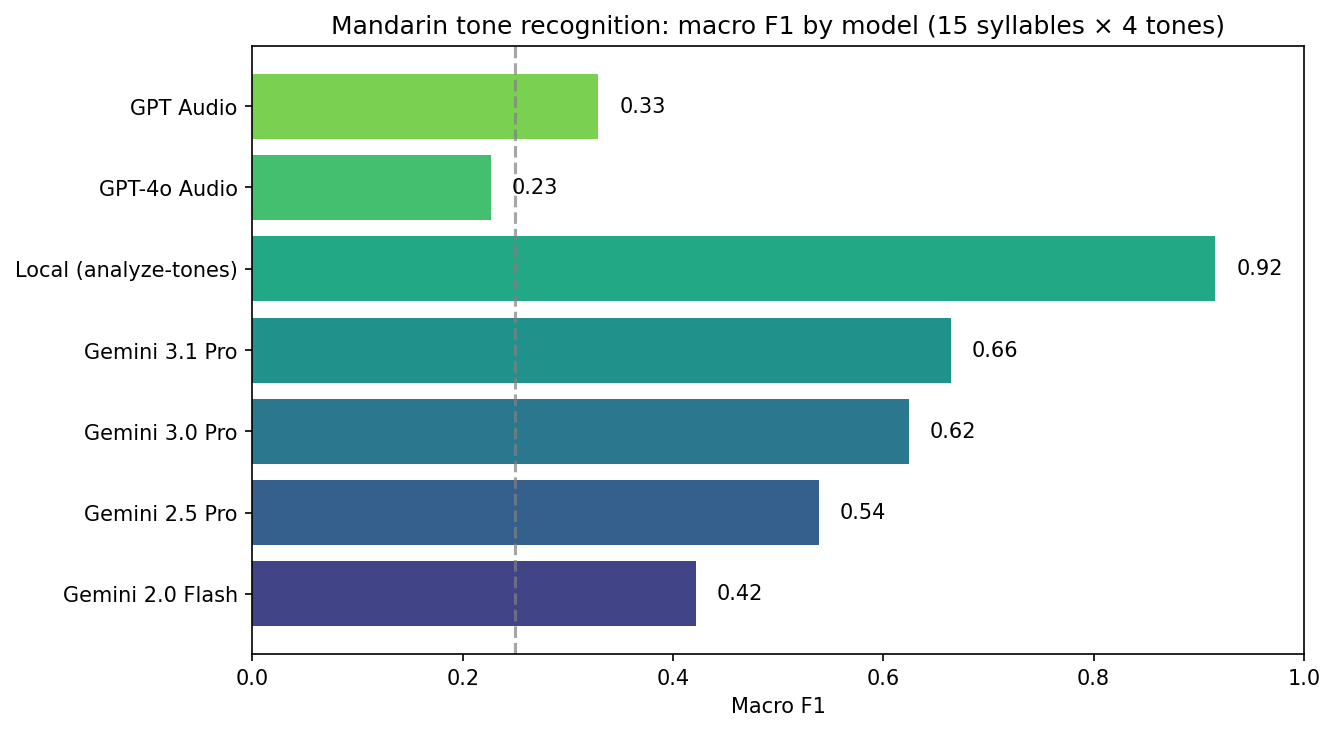
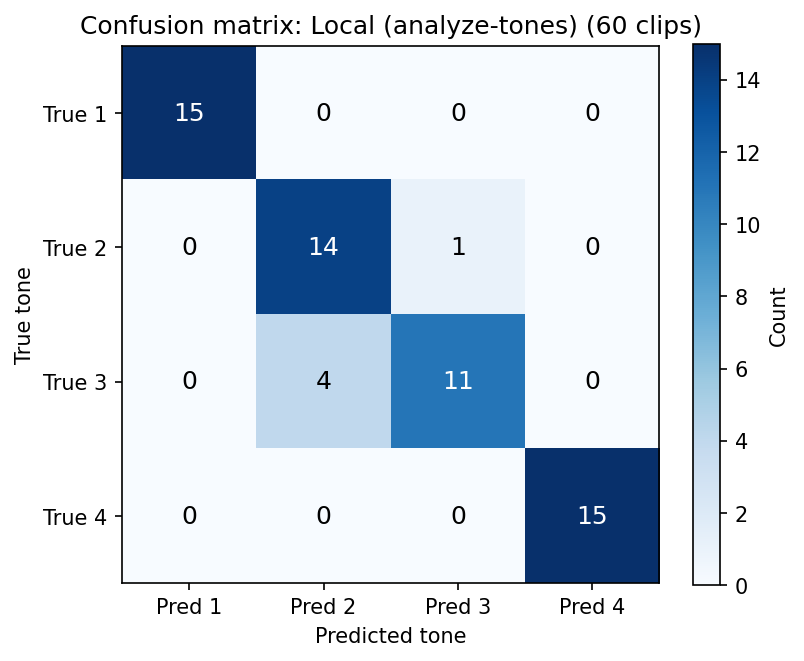
7. Repo and scripts
Everything is in the mandarin-tones repo:
scripts/generate_tones.py— build synthetic WAVsscripts/plot_pitch_contours.py— pitch contour figurescripts/run_tone_eval.py— send audio to models, write CSVscripts/analyze_tone_results.py— confusion matrices, P/R/F1scripts/plot_tone_results.py— macro F1 bar chart
For an up-to-date list of audio-capable models: python scripts/fetch_audio_models_from_litellm.py
(no API keys needed).